chunk-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Size of previous chunk, ifunallocated(P clear) | //prev_size +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Size of chunk, in bytes |A|M|P| //|A|M|P| -> |NON_MAIN_ARENA|IS_MAPPED|PREV_INUSE| mem-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | User data starts here... . . . . (malloc_usable_size() bytes) . next . | chunk-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | (size of chunk, but used for application data) | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Size of next chunk, in bytes |A|0|1| +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
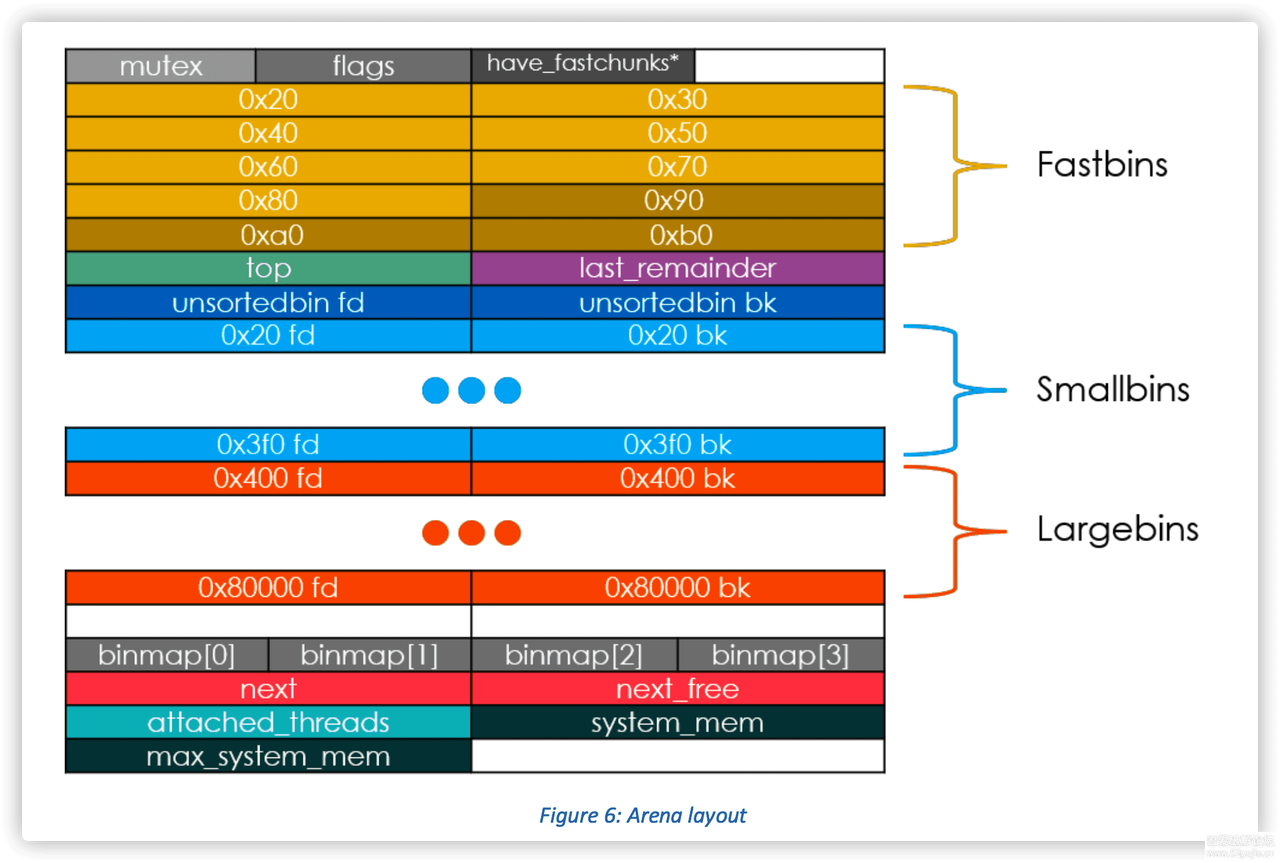
索引从 2 到 63 的 bin 称为 small bin,同一个 small bin 链表中的 chunk 的大小相同。两个相邻索引的 small bin 链表中的 chunk 大小相差的字节数为 2 个机器字长,即 32 位相差 8 字节,64 位相差 16 字节。
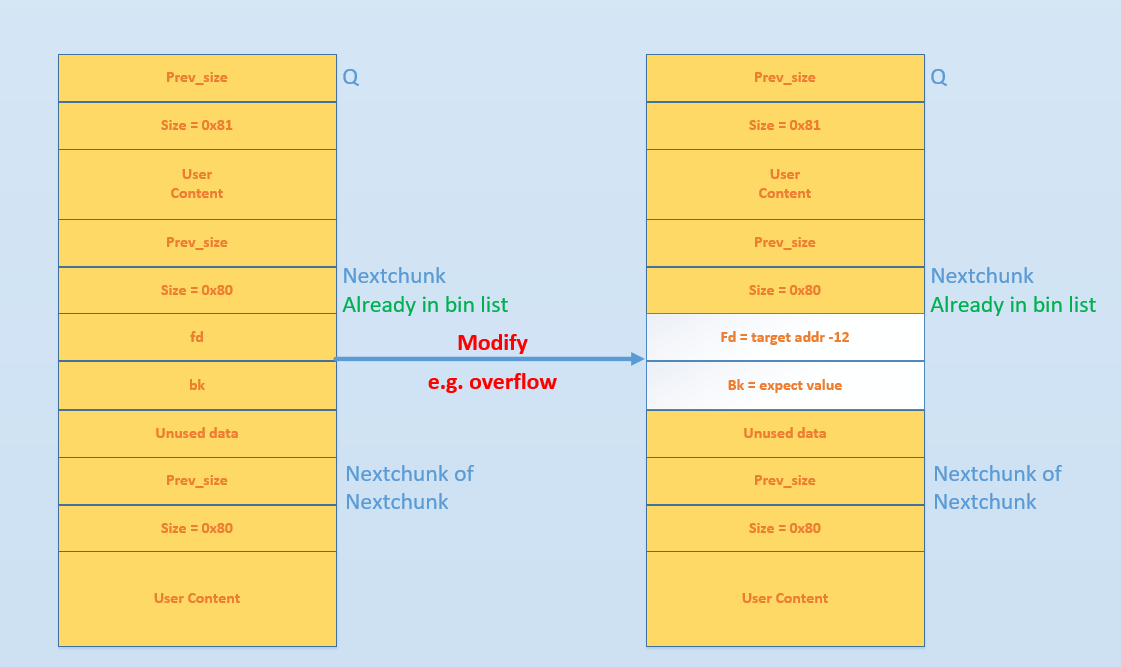
small bins 后面的 bin 被称作 large bins。large bins 中的每一个 bin 都包含一定范围内的 chunk,其中的 chunk 按 fd 指针的顺序从大到小排列。相同大小的 chunk 同样按照最近使用顺序排列。 此外,上述这些 bin 的排布都会遵循一个原则:任意两个物理相邻的空闲 chunk 不能在一起。 需要注意的是,并不是所有的 chunk 被释放后就立即被放到 bin 中。ptmalloc 为了提高分配的速度,会把一些小的 chunk 先放到 fast bins 的容器内。而且,fastbin 容器中的 chunk 的使用标记总是被置位的,所以不满足上面的原则。
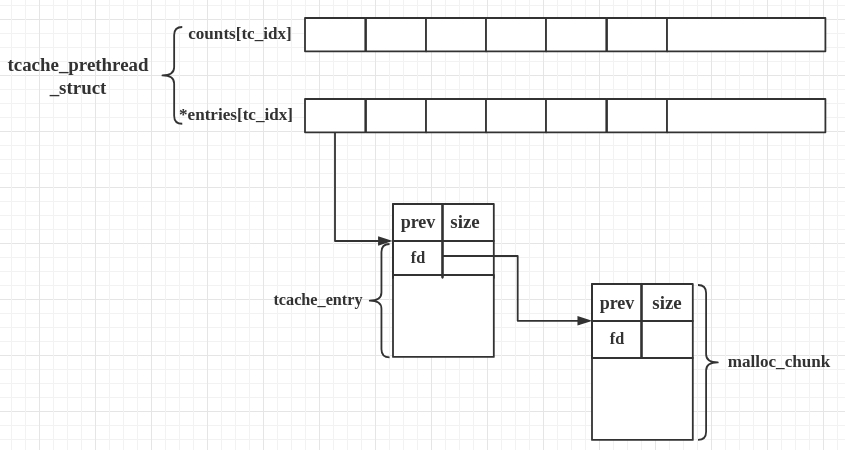
Tcache
头插头取,FILO tcache_perthread_struct
1 2 3 4 5 6 7 8 9 10 11 12 13 14
/* There is one of these for each thread, which contains the per-thread cache (hence "tcache_perthread_struct"). Keeping overall size low is mildly important. Note that COUNTS and ENTRIES are redundant (we could have just counted the linked list each time), this is for performance reasons. */ typedefstructtcache_perthread_struct { char counts[TCACHE_MAX_BINS]; tcache_entry *entries[TCACHE_MAX_BINS]; } tcache_perthread_struct;
/* Linked list for free arenas. Access to this field is serialized by free_list_lock in arena.c. */ structmalloc_state *next_free;
/* Number of threads attached to this arena. 0 if the arena is on the free list. Access to this field is serialized by free_list_lock in arena.c. */ INTERNAL_SIZE_T attached_threads;
INTERNAL_SIZE_T prev_size; /* Size of previous chunk (if free). */ //物理地址上上一个相邻chunk的大小(前提是其被free)否则会作为上一个chunk的数据段使用 INTERNAL_SIZE_T size; /* 这一个chunk的大小,包含头 Size in bytes, including overhead. */
structmalloc_chunk* fd;/* double links -- used only if free. */ structmalloc_chunk* bk;//双链表,仅在被free后使用,否则为分配给用户使用的数据段
/* Only used for large blocks: pointer to next larger size. */ //仅用于largebin,fd指向下一个大小不同的chunk;当有多个chunk大小相同时,指向大小相同chunk组成的子链的第一个chunk structmalloc_chunk* fd_nextsize;/* double links -- used only if free. */ structmalloc_chunk* bk_nextsize; };
/* malloc_chunk details: (The following includes lightly edited explanations by Colin Plumb.) Chunks of memory are maintained using a `boundary tag' method as described in e.g., Knuth or Standish. (See the paper by Paul Wilson ftp://ftp.cs.utexas.edu/pub/garbage/allocsrv.ps for a survey of such techniques.) Sizes of free chunks are stored both in the front of each chunk and at the end. This makes consolidating fragmented chunks into bigger chunks very fast. The size fields also hold bits representing whether chunks are free or in use. An allocated chunk looks like this: chunk-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Size of previous chunk, if allocated | | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Size of chunk, in bytes |M|P| mem-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | User data starts here... . . . . (malloc_usable_size() bytes) . . | nextchunk-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Size of chunk | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ Where "chunk" is the front of the chunk for the purpose of most of the malloc code, but "mem" is the pointer that is returned to the user. "Nextchunk" is the beginning of the next contiguous chunk. Chunks always begin on even word boundaries, so the mem portion (which is returned to the user) is also on an even word boundary, and thus at least double-word aligned. Free chunks are stored in circular doubly-linked lists, and look like this: chunk-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Size of previous chunk | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ `head:' | Size of chunk, in bytes |P| mem-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Forward pointer to next chunk in list | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Back pointer to previous chunk in list | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Unused space (may be 0 bytes long) . . . . | nextchunk-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ `foot:' | Size of chunk, in bytes | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ The P (PREV_INUSE) bit, stored in the unused low-order bit of the chunk size (which is always a multiple of two words), is an in-use bit for the *previous* chunk. If that bit is *clear*, then the word before the current chunk size contains the previous chunk size, and can be used to find the front of the previous chunk. The very first chunk allocated always has this bit set, preventing access to non-existent (or non-owned) memory. If prev_inuse is set for any given chunk, then you CANNOT determine the size of the previous chunk, and might even get a memory addressing fault when trying to do so. Note that the `foot' of the current chunk is actually represented as the prev_size of the NEXT chunk. This makes it easier to deal with alignments etc but can be very confusing when trying to extend or adapt this code. The two exceptions to all this are 1. The special chunk `top' doesn't bother using the trailing size field since there is no next contiguous chunk that would have to index off it. After initialization, `top' is forced to always exist. If it would become less than MINSIZE bytes long, it is replenished. 2. Chunks allocated via mmap, which have the second-lowest-order bit M (IS_MMAPPED) set in their size fields. Because they are allocated one-by-one, each must contain its own trailing size field. */
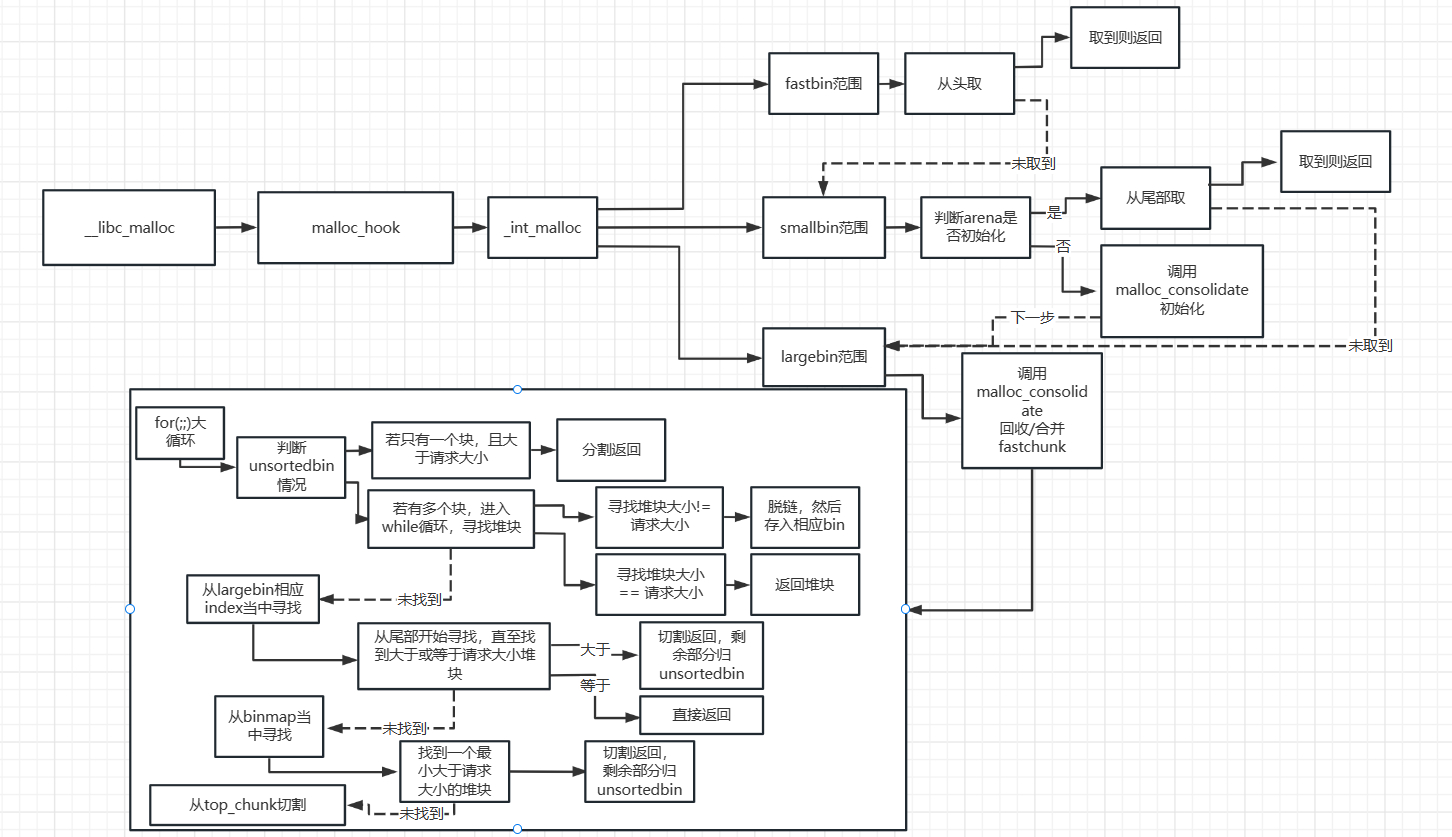
victim = _int_malloc (ar_ptr, bytes); //调用_int_malloc,返回分配chunk指针,参数一为arena指针,参数二为我们的需要分配的字节 /* Retry with another arena only if we were able to find a usable arena before. */ if (!victim && ar_ptr != NULL) //如果分配失败&&arena指针不为空 { LIBC_PROBE (memory_malloc_retry, 1, bytes); ar_ptr = arena_get_retry (ar_ptr, bytes); victim = _int_malloc (ar_ptr, bytes);//尝试重新分配 }
if (ar_ptr != NULL) (void) mutex_unlock (&ar_ptr->mutex);
/* 如果请求的size大小属于smallbin范围,我们则检查通用的bins数组. Since these "smallbins" hold one size each, no searching within bins is necessary. (如果是largebin范围, 我们必须等到 unsorted chunks 被处理为寻找最佳适配块. But for small ones, fits are exact anyway, so we can check now, which is faster.) */
if (in_smallbin_range (nb)) { idx = smallbin_index (nb); bin = bin_at (av, idx); //获取对应smallbin链表数组下标
/* 如果是个小请求,如果最近的remainder剩余块是unsortedbin当中唯一的块的话, 尝试使用他来分配 This helps promote locality for runs of consecutive small requests. 这是最佳适配的唯一例外 并且适用于当这里没有最佳适配的小堆块 */
/* 如果是large请求, 寻找最小适配块. Use the skip list for this. */
if (!in_smallbin_range (nb)) { bin = bin_at (av, idx);//获取bin指针
/* skip scan if empty or largest chunk is too small */ if ((victim = first (bin)) != bin && (unsignedlong) (victim->size) >= (unsignedlong) (nb)) //判断非空且最大块大于请求nb { victim = victim->bk_nextsize; while (((unsignedlong) (size = chunksize (victim)) < (unsignedlong) (nb))) //从链表尾部开始遍历,寻找到大于或等于他的块 victim = victim->bk_nextsize;
/* Avoid removing the first entry for a size so that the skip list does not have to be rerouted. */ //如果victim不为最后一个块,且相同大小堆块构成的子链表当中有两个或以上的相同大小的堆块 if (victim != last (bin) && victim->size == victim->fd->size) victim = victim->fd; //始终取第二个
++idx; bin = bin_at (av, idx); block = idx2block (idx); //宏,右移5个bit位 map = av->binmap[block]; bit = idx2bit (idx);
for (;; ) { /* Skip rest of block if there are no more set bits in this block. */ if (bit > map || bit == 0) { do { if (++block >= BINMAPSIZE) /* out of bins */ goto use_top; } while ((map = av->binmap[block]) == 0);
bin = bin_at (av, (block << BINMAPSHIFT)); bit = 1; }
/* Advance to bin with set bit. There must be one. */ while ((bit & map) == 0) { bin = next_bin (bin); bit <<= 1; assert (bit != 0); }
/* Inspect the bin. It is likely to be non-empty */ victim = last (bin);
/* If a false alarm (empty bin), clear the bit. */ if (victim == bin) { av->binmap[block] = map &= ~bit; /* Write through */ bin = next_bin (bin); bit <<= 1; }
else { size = chunksize (victim);
/* We know the first chunk in this bin is big enough to use. */ assert ((unsignedlong) (size) >= (unsignedlong) (nb));
remainder_size = size - nb;
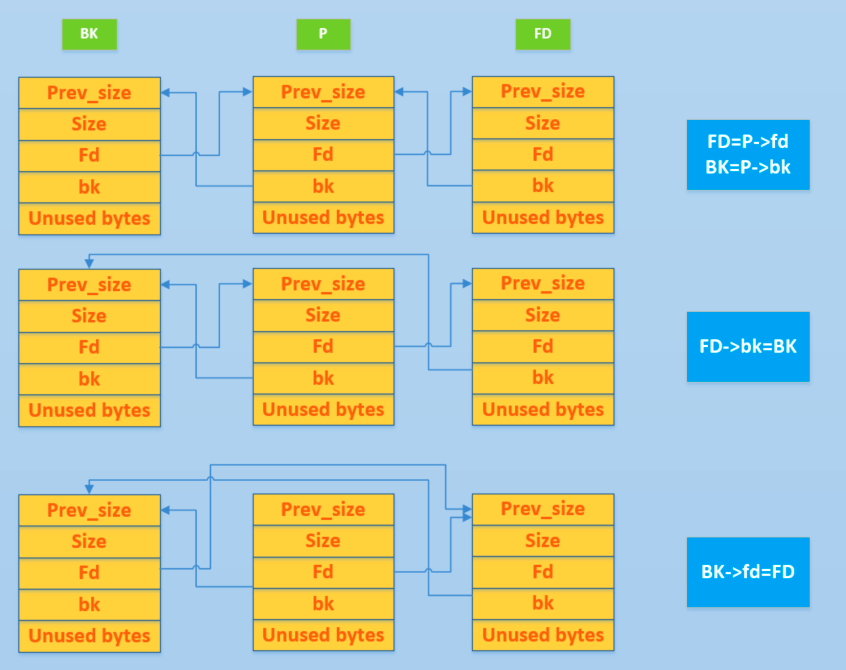
/* unlink */ unlink (av, victim, bck, fwd);
/* Exhaust */ if (remainder_size < MINSIZE) { set_inuse_bit_at_offset (victim, size); if (av != &main_arena) victim->size |= NON_MAIN_ARENA; }
use_top: /* If large enough, split off the chunk bordering the end of memory (held in av->top). Note that this is in accord with the best-fit search rule. In effect, av->top is treated as larger (and thus less well fitting) than any other available chunk since it can be extended to be as large as necessary (up to system limitations). We require that av->top always exists (i.e., has size >= MINSIZE) after initialization, so if it would otherwise be exhausted by current request, it is replenished. (The main reason for ensuring it exists is that we may need MINSIZE space to put in fenceposts in sysmalloc.) */
/* When we are using atomic ops to free fast chunks we can get here for all block sizes. */ elseif (have_fastchunks (av)) //如果topchunk不够,且有fastchunk,那么进行malloc_consolidate进行合并fast,然后在接着分配 { malloc_consolidate (av); /* restore original bin index */ if (in_smallbin_range (nb)) idx = smallbin_index (nb); else idx = largebin_index (nb); }